In this post, we show that it is possible to run the httomo computed tomography toolkit accelerated on consumer AMD hardware. While the toolkit was designed for acceleration with CUDA, it was relatively straightforward to make it work with ROCm. Our work so far should not be considered a complete port, but rather a proof of concept demonstrating the execution of several tomography pipelines on a Radeon GPU, with performance comparable to NVIDIA cards.
First we show the setup of the environment and the dependencies. This is followed by a description of the patches to the httomo stack that were required to enable execution on ROCm. These steps should be sufficient for readers to replicate our experiment on their own machines. In the final section, we present a performance comparison between the Radeon GPU and several CUDA-enabled accelerators.
Setting up the environment
We used an AMD Radeon RX 7900 GRE in an Ubuntu 24.04.3 LTS machine (kernel version: 6.17.0-14-generic). The ROCm stack was the latest release at the time of writing, at version 7.2.0, installed in the default location /opt/rocm-7.2.0. The symlink /opt/rocm also points to this location. Our Python environment was managed by Miniconda. First, create and activate the virtual environment:
conda create -c conda-forge -n rocm-tomography python=3.12 cython scipy=1.16 numpy=2.3 openmpi==4.1.6 h5py[build=*openmpi*]conda activate rocm-tomography
Httomo uses the CuPy package to interact with the GPU. At the time of writing, ROCm support is experimental, and CuPy does not provide prebuilt packages for ROCm 7.2. Some required patches have not yet been released. Therefore, CuPy needs to be built from source (commit 78bdcc35 or later):
git clone https://github.com/cupy/cupy.git && cd cupygit submodule init && git submodule updateCUPY_INSTALL_USE_HIP=1 ROCM_HOME=/opt/rocm pip install .
The other dependency that must be compiled from source for ROCm is the ASTRA toolbox. ASTRA includes experimental ROCm support, and our patch was also required for successful builds under ROCm 7.2. Commit d251e808 or later is needed. To build and install it:
git clone https://github.com/astra-toolbox/astra-toolbox.git && cd astra-toolbox/build/linux./autogen.sh && ./configure --with-hip=/opt/rocm --with-python --with-install-type=modulemake -j $(nproc) && make install
Patching httomo
The device-accelerated httomo tomography stack consists of four projects: ToMoBAR, httomolibgpu, httomo-backends and httomo. All of these required minor changes to run in the ROCm environment. For convenience of replication, we prepared these patches in our forks. Note that some of these patches are ad hoc, and not yet ready for upstreaming. A brief overview of the patches and the installation instructions is provided below:
- RadWay-Tech-Services/ToMoBAR at hip-tomography
- References to header
cuda_fp16.hmust be changed tohip_fp16.h - HIP include directory must be passed explicitly
- To install:
git clone --branch hip-tomography https://github.com/RadWay-Tech-Services/ToMoBAR.git && cd ToMoBAR && pip install.
- References to header
- RadWay-Tech-Services/httomolibgpu at hip-tomography
- Fix different implicit conversion rules in NumPy 2
- Relax dependency requirements to accept different versions of NumPy and CuPy
- To install:
git clone --branch hip-tomography https://github.com/RadWay-Tech-Services/httomolibgpu.git && cd httomolibgpu && pip install.
- RadWay-Tech-Services/httomo-backends at hip-tomography
- RadWay-Tech-Services/httomo at hip-tomography
- NumPy 2 related fixes
- Relax dependency requirements to accept different versions of NumPy and CuPy
- To install:
git clone --branch hip-tomography https://github.com/RadWay-Tech-Services/httomo.git && cd httomo && pip install.
- DiamondLightSource/httomolib
- No changes needed
- To install:
pip install httomolib
Benchmark results
With the above setup, we successfully executed complete tomography pipelines using the FBP (filtered backprojection), LPRec (log-polar reconstruction), and FISTA (Fast Iterative Shrinkage–Thresholding Algorithm) reconstruction algorithms. To place the performance results in context, we also executed the same pipelines on several NVIDIA accelerators, including both consumer and data center models.
Note that these measurements are not suitable for in-depth comparisons, as the accelerators did not share identical hardware, cooling systems, operating systems, and other configuration details. Rather, the purpose is to demonstrate that the AMD GPU delivers comparable performance with relatively modest porting effort.
Common parameters of the CUDA environments are the following:
- dkazanc/ToMoBAR at f9aea46d
- DiamondLightSource/httomolibgpu at beb94a6c
- DiamondLightSource/httomo-backends at 62b79673
- DiamondLightSource/httomo at 31e90103
- Python 3.12
- CUDA 12.9
- NumPy 1.26
- CuPy 13.6
The gist containing the full httomo pipeline can be found here. The pipeline can be executed with the command below, and the end-to-end runtime is printed to the terminal:
mkdir -p ~/work/httomo-outhttomo run ~/work/data.npz ~/work/tomo.yaml ~/work/httomo-out
Each configuration was run 3 times, of these the fastest results are collected in Table 1:
| FBP [s] | LPRec [s] | FISTA [s] | |
| Radeon RX 7900 GRE | 42.496 | 41.064 | 474.027 |
| GeForce RTX 3060 Ti | 57.65 | 65.17 | 779.135 |
| Tesla V100 | 73.187 | 69.848 | 519.951 |
| NVIDIA L40S | 67.556 | 67.463 | 280.512 |
The same results are shown on Figure 1. The values are normalized for the Radeon’s performance and inverted, so higher values stand for faster execution:
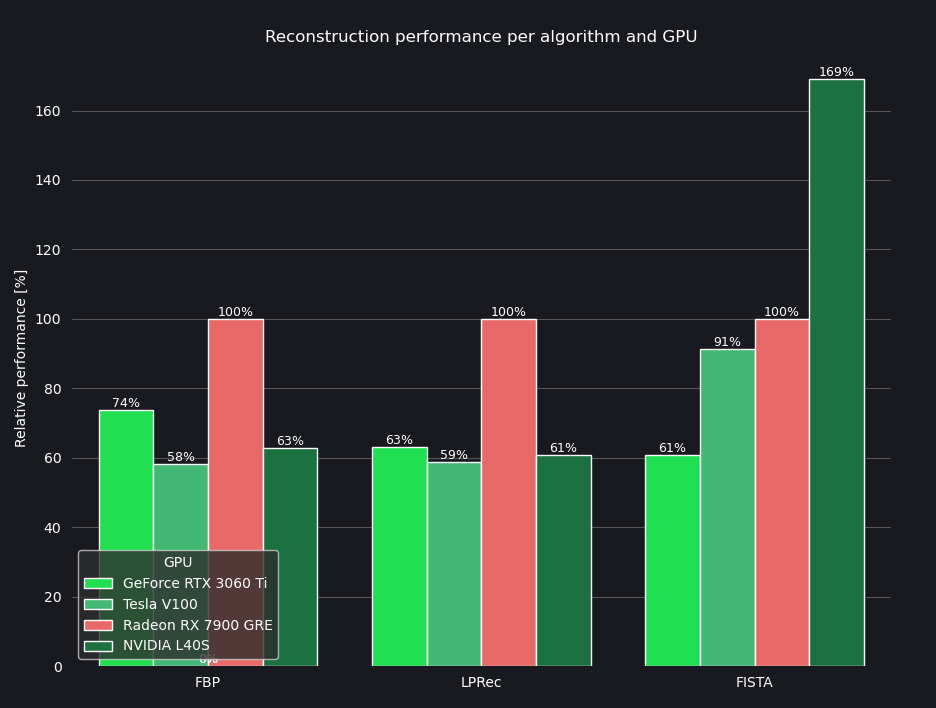
As can be seen, the Radeon offers performance comparable to both consumer and data center accelerators and performs particularly well against older NVIDIA cards. Note that the Tesla V100 and the L40S are deployed in a cloud environment, whereas the GeForce and the Radeon are installed in workstation PCs with more powerful CPUs and I/O subsystems. This may account for the relatively weaker performance of the otherwise more capable L40S in the FBP and LPRec reconstruction cases. The FISTA reconstruction is more compute-intensive, which is reflected in the L40S’s advantage in that case.
Summary
In summary, we have shown that the httomo tomography stack can be executed on consumer AMD GPUs using ROCm with relatively minor modifications. Although this work represents a proof of concept rather than a fully upstreamed port, the required patches are small, and support for ROCm within the compute ecosystem is steadily advancing. The benchmark results indicate that a Radeon RX 7900 GRE can deliver performance comparable to several NVIDIA consumer and data center GPUs, demonstrating that ROCm is a viable alternative for accelerating tomography workflows.
